\(E_1\) · RoPE 错位
局部位置与全局位置不一致,\(QK\) 相位错配。
RAG 文档重排、对话中段匹配等场景使 Prefix Cache 失效;业界改为块级独立 prefill 后拼接 KV 以提升复用率。 拼接后的注意力条件分布与 full-prefill oracle 不一致,导致精度与 TTFT 难以同时达标。
局部位置与全局位置不一致,\(QK\) 相位错配。
等价于局部 KV 与全局 KV 的表示差异。
块首汇聚峰拼接后扰动全局注意力 mass。
出题指标:KV 复用率 \(\ge 80\%\),TTFT 降低 \(\ge 70\%\),精度损失 \(< 1\%\); 覆盖 Qwen3-32B、DeepSeek-V3.2、GLM-5 及 RULER、LongBench;在 UCM 框架验证。
块级 KV 复用省下了重复计算,却破坏了「整段上下文下的条件分布」。 本方案在统一全局位置编码之后,用数据结构修复与算子纠偏两条线协同, 把混合缓存中的局部表示逐步拉向 full-prefill 的全局 oracle。
| 误差 | 本质 | 对策 | 机制 |
|---|---|---|---|
| \(E_1\) | 几何不一致 | RoPE 归位 | 解析旋转 |
| \(E_2\) | 局部 KV \(\neq\) 全局 KV | \(\tau\) + \(F\) 写回 | 数据结构物理矫正 |
| \(E_3\) | mass 畸变 | \(F(Q,L)\) | 注意力分布纠偏 |
协同:\(\tau\) 改 KV 本体,\(F\) 改 attention 映射。 当 \(\tau \ge |B|/2\) 且非对称覆盖时,\(L \approx L^{\star}\),\(F\) 内各抑制/倾斜项为空,自动退化为标准自注意力,详见下文分析。
本质:省算破坏整体性;修复是以最小重算代价重建上下文关系。
两点论:兼顾复用、时延、精度;抓住边界、层敏感性与假 Sink。
重点论:在有限 \(\tau\) 下结构化修复,而非全量重算。
量变→质变:\(\tau\) 增大使物理修复覆盖后缀;\(F\) 的纠偏项随 \(L\to L^{\star}\) 自动消失。
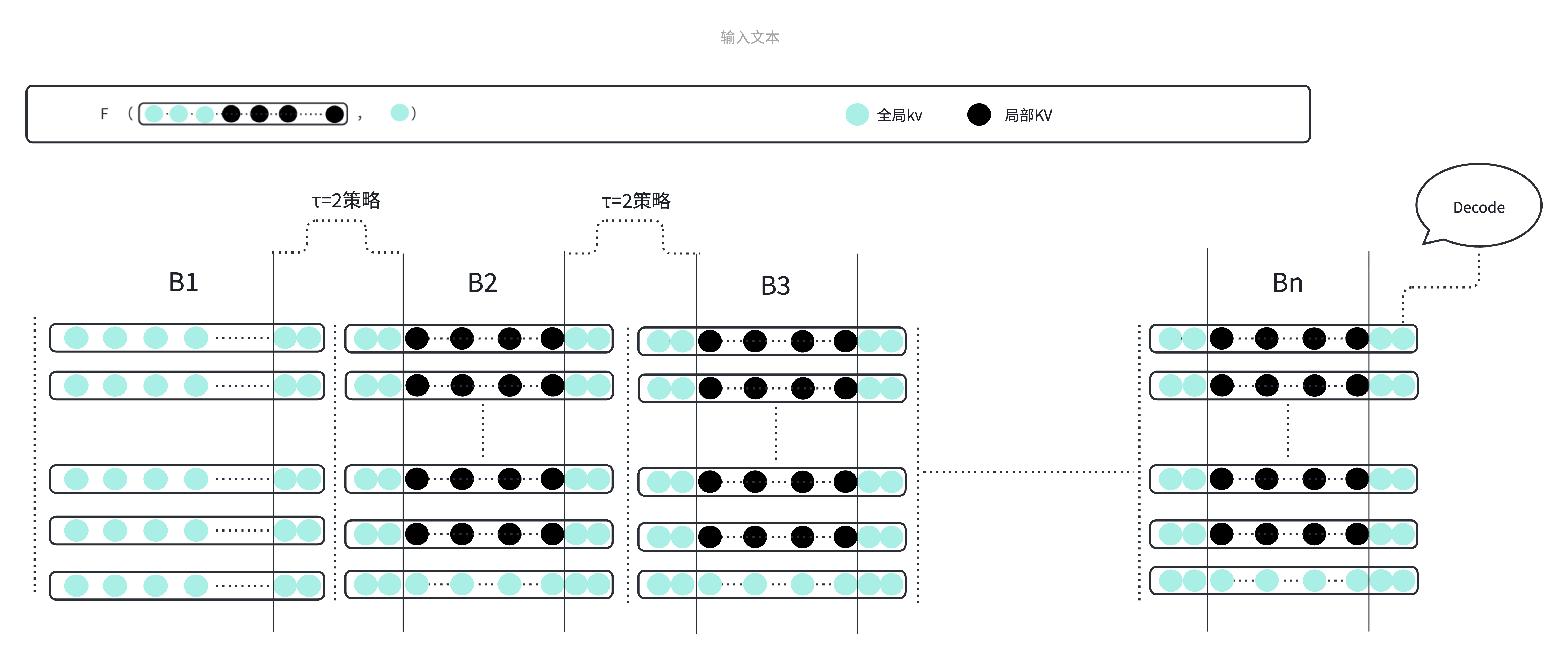
圆点表示各层 KV 状态;边界 τ 窗口经 \(F\) 物理重算后由黑变蓝;Decode 阶段继续调用同一 \(F\)。
\(S = B_1 \oplus B_2 \oplus \cdots \oplus B_m\),其中第 \(i\) 块为 token 区间
\[ B_i = x_{s_i : e_i} \]
\(s_i\):块 \(B_i\) 在整段序列中的起始全局下标(含);
\(e_i\):结束下标(不含,半开区间,与 Python 切片一致)。
例:\(s_1=0,\, e_1=384\) 表示 \(B_1\) 占据位置 \(0,1,\ldots,383\)。
对每个全局位置 \(t\)、层 \(\ell\):
\[ L[t,\ell] = \bigl(\hat K_{t,\ell},\; \hat V_{t,\ell},\; m_t\bigr) \]
紧凑写法(说明型,非公式定义):
\[ L \;\approx\; [\;\underbrace{K^{\mathrm{global}}V^{\mathrm{global}}}_{B_1\;\text{全局KV}},\;\underbrace{K^{\mathrm{local}}V^{\mathrm{local}}}_{B_2\;\text{加载时为局部KV}},\;\ldots\;] \]
上标 global / local 表示 KV 的质量类型, 下标表示块编号——并非每个块固定为某一类: B₁ 在真前缀条件下通常全为 global;B₂ 加载时多为 local,经 \(\mathcal{T}_\tau\) 上 \(F\) 写回后可变为 global。
接缝 \(B_i \mid B_{i+1}\) 的对称窗口:
\[ \mathcal{T}^{(i)}_{\mathrm{seam}} = [\,s_i,\, e_i)\cap[e_i-\tau,\,e_i) \;\cup\; [\,s_{i+1},\, e_{i+1})\cap[s_{i+1},\, s_{i+1}+\tau) \]
非对称规则(B₁ 为真前缀):接缝 \(B_1|B_2\) 不重算 \(B_1\) 尾部 \(\tau\) token,预算补至 \(B_m\) 尾部 \(\tau\) token。
重算占比 \(|\mathcal{T}_\tau|/N\);工程目标:\(\le 5\%\) 且精度达标。
\(F\) 是在标准自注意力之上的结构感知扩展,输入 query 集合 \(Q\) 与混合缓存 \(L\),输出与 oracle 一致的隐藏表示:
\[ F(Q,\,L) \;=\; \Attn\!\bigl(Q,\, \hat K,\, \hat V;\, \mathcal{M}_{\mathrm{corr}}(L)\bigr) \;\approx\; \Attn(Q,\, K^{\star},\, V^{\star}) \]
其中 \(\mathcal{M}_{\mathrm{corr}}(L)\) 为由 \(L\) 元数据导出的纠偏项,明确为:
\[ \mathcal{M}_{\mathrm{corr}}(L) = \{M_{\mathrm{local}}(j),\; M_{\mathrm{sink}}(j)\} \]
\[ M_{\mathrm{local}}(j)=\mathbb{1}[\type_j=\mathrm{local}], \qquad M_{\mathrm{sink}}(j)=\mathbb{1}[j\in\mathcal{S}'] \]
\(L^{\star}\):对完整 \(S\) 一次 full-prefill 的 oracle 缓存(对照基准,非在线必算)。
| 步骤 | 操作 | 输出 | 误差 |
|---|---|---|---|
| ① | 块匹配,加载 KV,构造 \(L^{(0)}\) 及元数据 \(m_t\) | 混合缓存 | — |
| ② | 全局 RoPE 归位:\(\hat K\leftarrow R(g_t)R^{-1}(t_{\mathrm{loc}})\hat K\) | \(L^{(1)}\) | \(E_1\) |
| ③ | 在 \(\mathcal{T}_\tau\) 上调用 \(F\) 做因果前向并写回 KV,\(\type_t\leftarrow\mathrm{global}\) | \(L^{(2)}\) | \(E_2\) |
| ④ | Prefill 剩余段 + Decode:调用 \(F(Q,L^{(2)})\) 推理(单 token 或批量 query) | 隐藏态 / 生成 | \(E_3\) |
\(F\) 在标准 logits 上叠加可开关的纠偏项,核心理念: 局部 KV 降权 / 全局 KV 相对倾斜,块首假 Sink 抑制;不含额外边界结构项——跨块语义由步骤 ③ 的 \(F\) 物理写回负责。
\[ s_{ij} = \frac{\langle q_i,\,\hat k_j\rangle}{\sqrt{d}} + \underbrace{\alpha\,\mathbb{1}[\type_j=\mathrm{local}]}_{\text{局部 KV 倾斜项}} + \underbrace{\beta\,\mathbb{1}[j\in\mathcal{S}']}_{\text{假 Sink 抑制项}} \]
\[ o_i = \sum_j \mathrm{softmax}_j(s_{ij})\,\hat v_j \]
定义纠偏掩码集合(与 §5.4 一致):
\[ \mathcal{M}_{\mathrm{corr}}(L) = \{M_{\mathrm{local}}(j),\;M_{\mathrm{sink}}(j)\}, \;\; M_{\mathrm{local}}(j)=\mathbb{1}[\type_j=\mathrm{local}], \;\; M_{\mathrm{sink}}(j)=\mathbb{1}[j\in\mathcal{S}'] \]
当 \(\mathcal{T}_\tau\) 足够大(如 \(\tau\ge |B|/2\) 且非对称覆盖 \(B_{2:m}\))时:
\[ F(Q,L) \;\equiv\; \mathrm{Softmax}\!\left(\frac{QK^{\top}}{\sqrt{d}}\right)V \]
即自动退化为标准 Transformer 自注意力。 此时计算上仍对后缀做了完整因果 prefill,复用上主要保留 \(B_1\) 缓存收益。
Prefill vs Decode:同一 \(F\);Prefill 在 \(\mathcal{T}_\tau\) 含 KV 写回,Decode 仅追加 query,同质异量。